Information Extraction, Integration and Search
(December 10, 2016) Update: I am no longer actively working on information extraction,
or integration, except in the context of data analytics and versioning, and some other one-off projects. Please head on
over to the  website to find out more. This page is no longer actively maintained.
website to find out more. This page is no longer actively maintained.
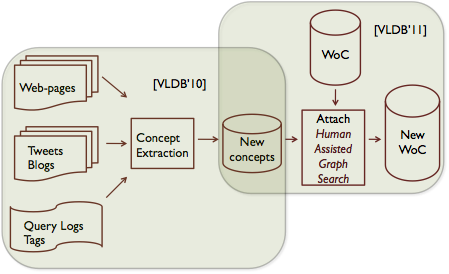
Robust Concept Extraction and Integration
Along with folks at Kosmix (now acquired by Walmart), we looked at the problem of generating concepts — i.e., entities, items and ideas that users are interested in and searching for. However, the problem is that users typically do not simply type in their concept of choice into the search bar, but also extra terms, or other concepts. For example, a person searching for “Martin Scorcese” might type in “Martin Scorcese Departed”. We used ideas from association rule mining to figure out whether a sequence of n words represents a concept, relative to the n+1 word sequences that contain it, or the n-1 word sequences contained by it. We proved some theoretically desirable properties of our approach, and experimentally demonstrated effectiveness on a dataset of query logs. Our solution was deployed internally at Kosmix to enhance their concept hierarchy. The next step to this work was to find where to attach an extracted concept to a topic hierarchy. Since this is a task not easily done by computers, we looked at using human involvement to assist our search. We devised algorithms to find the minimal set of questions to ask humans to identify the correct category.
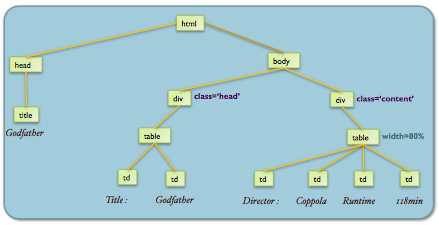
Robust Metadata Extraction
Web-pages that are script or template based prove to be invaluable for extraction of concept metadata. For instance, it is easy to ask humans to annotate a few web-pages and learn a web wrapper to extract all metadata from a script-based website such as Yelp, Amazon, Ebay and so on. (For instance, restaurant phone numbers may be extracted from Yelp.) However, these web-pages change often, and the web wrappers learnt for the web-pages may no longer extract correct data. Along with folks at Yahoo! Research Bangalore, we looked at the wrapper maintenance and management problem. We were able to design efficient algorithms that output theoretically optimal robust wrappers for two different change models, and found that these wrappers perform orders of magnitude better than existing wrappers in terms of fault tolerance.
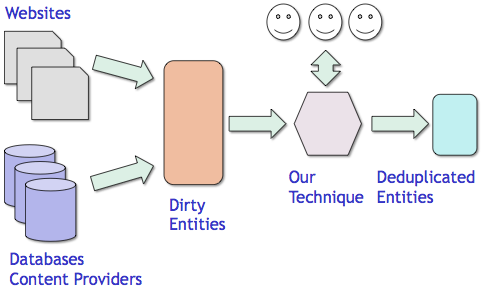
Expert Input in Extraction and Integration
We have worked on various problems around debugging large information extraction pipelines, and building better classifiers for entity resolution, both using as few expert human input as possible (thereby minimizing cost and time).
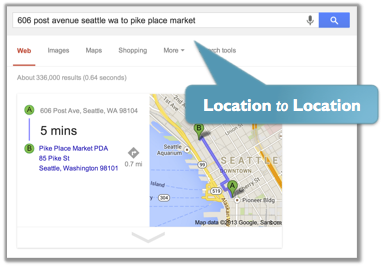
Parsing-Based Keyword Search
Along with folks at Microsoft Research, we worked on the problem of matching keyword search queries to a large collection of prespecified patterns (such as “Restaurant” near “Location”) and a large database of facts. Our solution is the first efficient solution with guarantees; and the implementation of our approach scaled easily to the large dataset sizes at Microsoft.