Crowd-Powered Analytics
(December 10, 2016) Update: Please head on
over to the  website for the latest. This page is no longer actively maintained.
website for the latest. This page is no longer actively maintained.
There are many tasks done easily and better by people than by current computer algorithms: tasks dealing with understanding and analyzing images, video, text and speech, as well as subjective opinions and abstract concepts.
Due to the proliferation of cheap and reliable internet connectivity, a large number of people are now online and willing to answer questions for monetary gain. There are a number of human computation (a.k.a. crowdsourcing) marketplaces — Mechanical Turk, oDesk, LiveOps, and others — that enable workers to find tasks easily.
sCOOP is a project whose broad theme is to leverage people as processing units, much like computer processes or subroutines, to achieve some global objective. A primary focus of sCOOP is to optimize this computation — while there may be many ways to orchestrate a particular task, our goal is to use as few resources (e.g., time, money) as possible, while getting equally good or better results as unoptimized computation.
Optimizing Crowd Algorithms
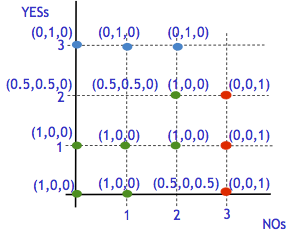
Here, the goal is to optimize some fundamental data processing algorithms where the unit operations are performed by people. Examples of algorithms include: sorting, clustering, classification, and categorization. Over the last year, we worked on algorithms for gathering, max, filtering, graph search, and lineage debugging. The goal of gathering is to extract as many entities as possible from a specific domain, e.g., find all events happening today in New York. The goal of the Max problem is to find the best item among a given set of items (e.g., photos, videos or songs), given a budget on the number of pairwise comparisons that may be asked of humans. We also looked at the Filtering problem, where we wanted to find which items in a given data set satisfy a given set of properties (that may be verified by humans), and the goal was to find the cost-optimal filtering algorithm, given constraints on error and time. We also considered the problem of human-assisted graph search, which has applications in many domains that can utilize human intelligence, including curation of hierarchies, image segmentation and categorization, interactive search and filter synthesis.
Crowdsourcing Quality Management
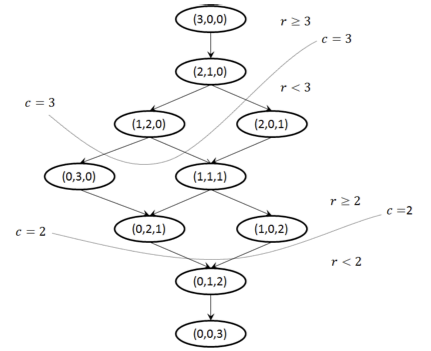
The goal of crowdsourcing quality management is to manage the quality of task responses, as well as the quality of the workers. We have studied various aspects of this problem, including generating confidence intervals for worker quality, determining global optimal worker quality estimates, and determining whether to hire or fire workers.
Declarative Crowdsourcing
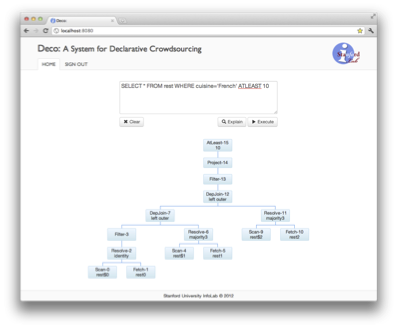
Here, the goal is to combine human and algorithmic computation with traditional database operations in order to perform complex tasks. This combination involves several optimization objectives: minimizing total elapsed time, minimizing the monetary cost to perform human computation (minimizing the number of questions and pricing them accordingly), and maximizing confidence in the obtained answers. Our proposed approach views the crowd-sourcing service as another database where facts are computed by human processors. By promoting the crowd-sourcing service to a first-class citizen on the same level as extensional data, it is possible to write a declarative query that seamlessly combines information from both. The system becomes responsible for optimizing the order in which tuples are processed, the order in which tasks are scheduled, whether tasks are handled by algorithms or a crowd-sourcing service, the pricing of the latter tasks, and the seamless transfer of information between the database system and the external services. Moreover, it provides built-in mechanisms to handle uncertainty, so that the developer can explicitly control the quality of the query results. Using the declarative approach, we can facilitate the development of complex applications that combine knowledge from human computation, algorithmic computation, and data. Our current design and details of our initial prototype can be found in the Deco paper.
Datasift: Crowd-Powered Search
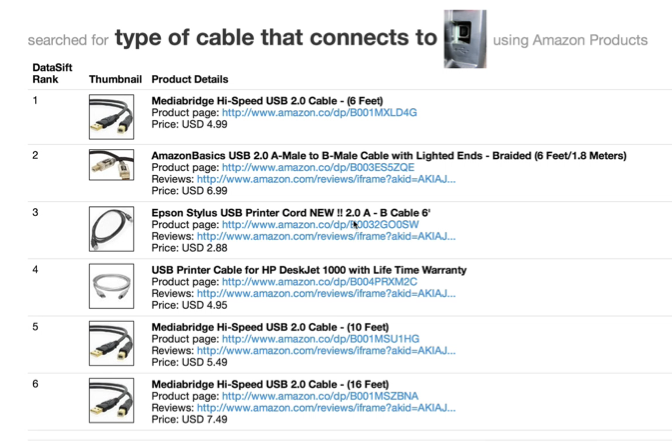
Traditional search engines are unable to support a large number of potential queries issued by users, for instance, queries containing non-textual fragments such as images or videos, queries that are very long, ambiguous, or those that require subjective judgment, or semantically-rich queries over non-textual corpora. We have developed DataSift, a crowd-powered search toolkit that can be instrumented over any corpus supporting a keyword search API, and supports efficient and accurate querying for a rich general class of queries, including those described previously.