Interactive and Approximate Analytics
(December 10, 2016) Update: Please head on
over to the  website for the latest on approximate visualization work,
to the
website for the latest on approximate visualization work,
to the  website for the scalable spreadsheet work,
and to the
website for the scalable spreadsheet work,
and to the  website for the versioning and collaborative analytics work. This page is no longer actively maintained.
website for the versioning and collaborative analytics work. This page is no longer actively maintained.
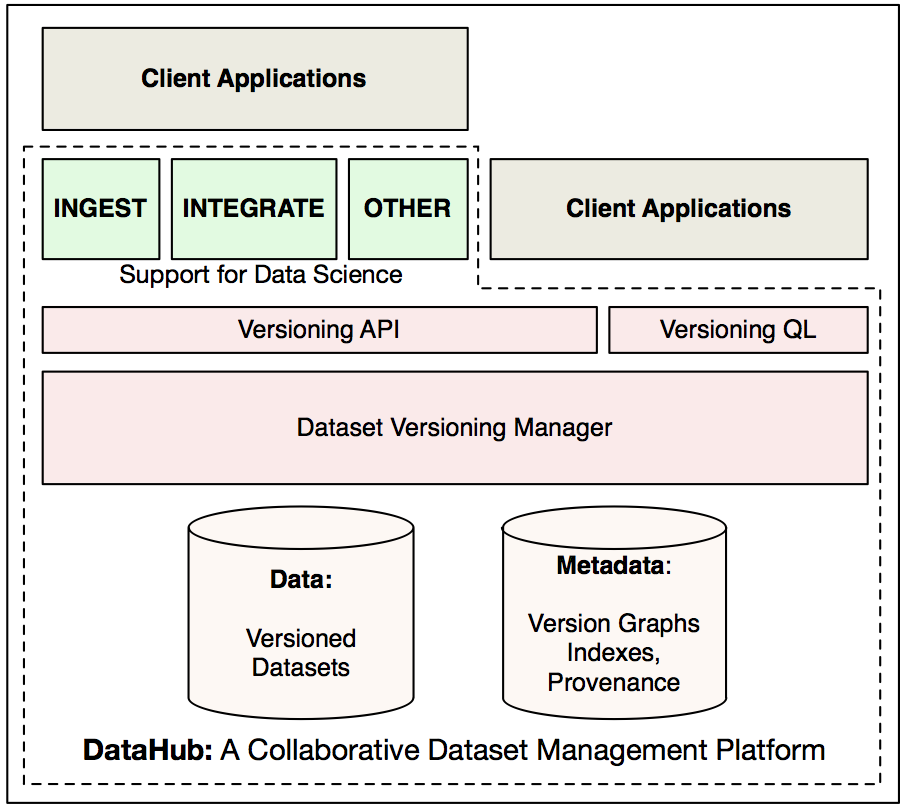
DataHub: Collaborative Dataset Version Management at Scale
Relational databases have limited support for collaboration. Inspired by software version control systems like GitHub, we're building DataHub (or "GitHub for Data") is a system that enables collaborative data science by keeping track of large numbers of versions and their dependencies compactly, and allowing users to progressively clean, integrate and visualize their datasets building on top of this version control system.
Project Website: Link

NeedleTail: A System for Browsing
Analysts performing data exploration often browse; i.e., pose a query and then examine the details of a small number of the resulting records (independent of the size of the query result). In a typical session, analysts will start with one browsing query, examine a few of the resulting records, and then repeatedly issue new browsing queries by adding or removing predicates from their previous queries until they eventually gain a better understanding of the dataset. Unfortunately, traditional database systems are not engineered towards browsing: instead, these systems operate in an all-or-nothing manner, taking as long as it takes to return the entire set of results, however large it may be. To this end, we have developed NEEDLETAIL, a database system tailored towards an alternative database query interaction paradigm: browsing. NEEDLETAIL makes efficient use of memory to store special bitmap indexes (called “swift indexes”) that enable rapid retrieval of a small number of query result records. A key optimization challenge is ensuring that these indexes respect memory constraints while imposing as little additional retrieval overhead as possible.
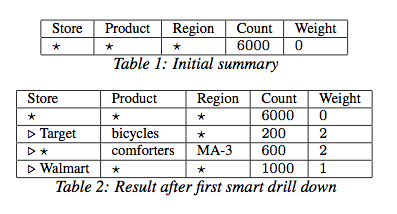
Smart Drill-Down: An Interactive Exploration Operator
Smart drill-down is an operator for interactively exploring a relational table to discover and summarize “interesting” groups of tuples. Each group of tuples is described by a rule. For instance, the rule (a, b, *, 1000) tells us that there are a thousand tuples with value a in the first column and b in the second column (and any value in the third column). Smart drill-down presents an analyst with a list of rules that together describe interesting aspects of the table; the analyst can click on any portion of these rules to further drill-down on desired portions.
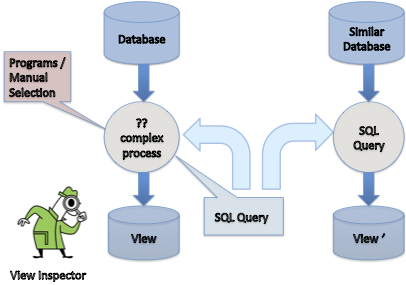
Synthesizing Queries
Many novice data analysts have trouble understanding and crafting queries in database query languages like SQL. Our goal is to simplify querying for such analysts, by guiding them to the query that they have in mind without much effort. In our ICDT’10 paper, given that an analyst has selected a subset of tuples of interest, we developed algorithms that automatically generate the most succinct and accurate query that captures that subset. We examined this problem as a tug-of-war between three forces: Query family (e.g., Conjunctive queries), Approximation (e.g., I'm fine with capturing 80% of the right tuples), Succintness (e.g., Give me a query that is the smallest) and tried to evaluate the complexity of solving the problem. In our VLDB’11 paper, we designed algorithms for interacting with the analyst (by asking as few questions as possible) to identify the predicates of interest.
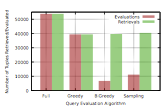
Expensive Query Optimization
User Defined Function(UDFs) are used increasingly to augment query languages with extra, application dependent functionality. UDFs tend to be expensive, either in terms of monetary cost or latency. We studied ways to efficiently evaluate selection queries involving UDFs. We provided a family of techniques for processing queries at low cost while satisfying user-specified precision and recall constraints. Our techniques are applicable to a wide variety of scenarios, such as when selection probabilities of tuples are available beforehand, when this information is available but noisy, or when no such prior information is available. We also generalize our techniques to more complex queries. On real datasets, our techniques achieve significant savings in cost of up to 80%, while incurring only a small reduction in accuracy.