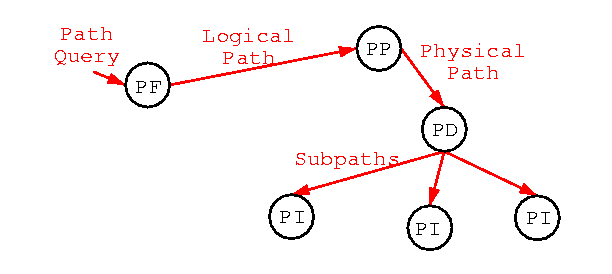
A Path is a data flow through a graph of operators and connectors.
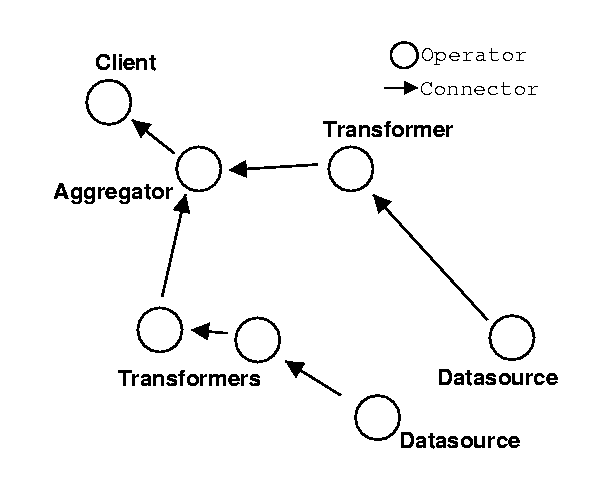
The data that flows through a path is packetized as an Application Data Unit (ADU). Although there is typing information associated with each ADU, the structure and content of the ADU defined at the application-level, and not by Paths.
Applications of Paths include transformational services to support heterogenous end-devices, telephony-style communication between heterogeneous devices, "clusterization" of database queries, internet services, composable applications, etc.
Paths can perhaps be thought of as "application-level active networks," or even as data-flow computing, where the building blocks are application modules rather than machine instructions.
Operators are composable, mobile pieces of code, along with an (XML) description of the operator. These descriptions are primarily a strongly-typed interface: the number and types of their inputs and outputs. They also include information on where to get the code from, and how to run it.
Operators can be:
Connectors, like operators, are also mobile code. However, connectors are described by their transport characteristics, and are type-neutral. Some of the characteristics that might describe a connector include its reliability, latency, in-order delivery, QoS, and security levels.
The typing system consists of a multiple-inheritance type hierarchy with key/value pairs as type attributes. A type can also be related to some other type (e.g., with a list type would have a "contains" relationship to the type of data it contains). Types do not generally specify any structure to the data they describe. It is assumed that if two applications agree on the name of a type, they also agree on it's structure and semantic interpretation (one way to make this more explicit is to embed a language-specific typename into the path-type).
Here is an illustration of one simple type hierarchy.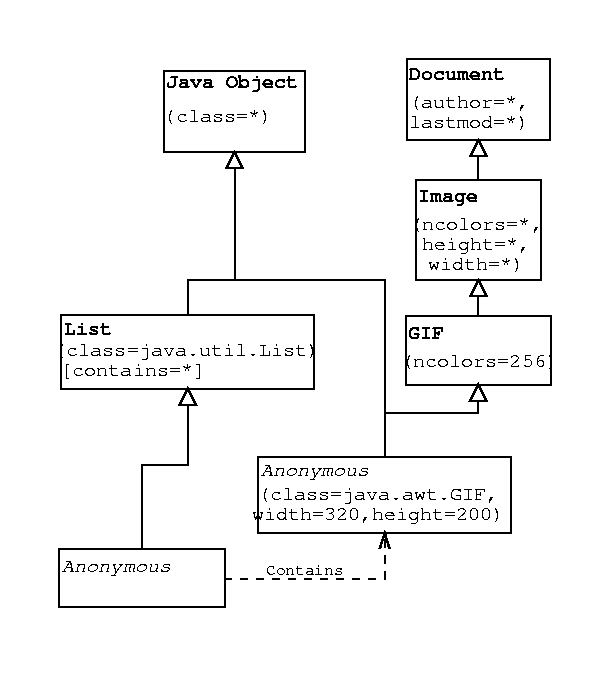
It's important to note that the Paths architecture does not specify any particular ontology or type hierarchy.
Since operators, especially type transformers, are to a large extent defined by their type interfaces, it's important to understand how much information can and should be represented in a data type. This is an open issue.
Vocabulary:
The process of creating a path is divided into three stages:
Because the path creation process is itself a path, new stages can be added and existing stages can be replaced easily. Examples of possible useful stages includes: adding caching operators around operators in a logical path, parallelizing operators within a path, adding supervisor and logging operators.
Automatic Path Creation (APC) is the process taking a partial path of unconnected operators and connecting them, adding type transformers to the path as necessary to ensure type-correctness. E.g., given a path consisting of a data sink which only accepts images and a data source which generates text, APC would add to the path an operator which rendered the text into an image.
APC is one example of the Path Finder operator in the previous section. The output of APC is a logical path.
Limitations on APC include it's reliance on transformational semantics to decide when to insert operators into the path, and it's non-linear running time, ~O(n2), where n is the length of the path.
Despite this, APC seems like a useful tool to enable any-to-any communication between heterogeneous devices and services.
I can see two different ways of using paths to develop applications:
Regardless of how paths are used to develop applications, there will be the question of how to connect non-path-aware and non-path devices/programs to paths. To a certain extent, devices can be wrapped by an operator and made to look like part of a path. But how do programs communicate with a path if they are not a part of it? -> Are paths long-lived, allowing clients to send it requests, or are paths short-lived, with a single path per client request? If the latter, who handles creating a path for the client's request? My assumption is that the answer to these questions depends on the particulars of the functionality that's being provided by the path. The architecture should support all options, and what is actually being done should not affect the programming model for individual operators, only the interaction between the "outside world" and the "paths world."