February, 2011
The promises of Google App Engine are extremely seductive. Free initial setup costs. Easy APIs to a data store, memcached, urlfetch, task queue, image processing, and more. Unlimited scalability on Google's infrastructure, priced exactly to what you consume. It was for all these reasons that I had launched around 10 separate apps on GAE prior to launching what would become my final App Engine app in February, 2010. I'm writing this post to document my experience with Google App Engine, to counsel those who reach a similar place, and to add my $0.02 to the debate around cloud services.
My net assessment: Google App Engine is appropriate for apps with no scalability requirements. If you can count the number of concurrent users on two hands, or need merely to create a proof-of-concept for which you are willing to completely throw away your code base, then App Engine is a defensible choice. For applications with any scale or ambition to scale, I cannot recommend App Engine. For applications on GAE already that are beginning to scale, get off as soon as you can before your data set grows to an unwieldy size and becomes un-exportable.
Two caveats: first, I was employed by Google many years ago. I am friends with multiple people who have worked on Google App Engine, and they have always been extremely nice and responsive. They are good, professional, smart people, and I know they are working hard to make GAE better. In no way is this post meant to undermine their efforts, creativity or intelligence; this is meant as an honest and empirical critique of a product, period. Second, I am not a hardcore server engineer, and I instead tend to gather a little bit of information about a lot of different things, meaning when it comes to bootstrapping products, I'm reasonably effective. This post is for people out there who are bootstrappers like me.
It was the second point that led me to Google App Engine originally. I wanted to learn more about iOS development (known as iPhone development back then), and so for my first app I decided to build a social dating app. I was not a server engineer, and as such wanted to minimize burden of server management as much as possible. At the time, Google App Engine seemed like a logical choice. No need to become a DBA, no need to deal with server provisioning, and zero upfront hosting costs.
GAE made sense for us in the very beginning, when we had minimal traffic and were spending around $5-10/day. We launched initially in March; in late July, we released a version of our app that caught a wave, and everything changed. Latency grew, costs skyrocketed, we almost ran out of money and shut it all down. Rather that do a walk-through of the highs and lows of the business, let me simply summarize the key problems we faced with GAE:
One would think that any database backed by Google would be robust. After all, this is the same code powering apps like Gmail. For whatever reason, however, the GAE database has extraordinarily high variance. Requests will inexplicably go from tens to thousands of milliseconds to serve. At a high load (50+ requests/sec), we saw database timeouts tens of times per minute, and often more (every request in a 10-60 sec period would fail). To Google's credit, it provides an outstanding reporting infrastructure to notice these failures, but the failures were inexplicable and without remedy.
If you try to compare GAE side-by-side with a service like EC2/S3, it seems like they are roughly approximate. Indeed, data storage and transfer is cheaper on GAE than Amazon. Storage and bandwidth, however, are not the scarce resource. CPU time is the true cost. As it turns out, most of your CPU time will be spent querying the database. As per point 1, the database is extremely high latency, and entirely outside of your control, meaning for many query types you are facing high costs about which you can do nothing. Ironically, the faster Google makes its database, the less they can charge (EC2, with its per-hour pricing structure, does not face this moral hazard). Memcaching is the standard answer to speeding things up, but there are query types I faced where I needed to store state or lookup data for which memcache was not appropriate.
Case in point: Google has an example of how to use GAE to do location-based queries. This sample code generates tens of database requests each time it is executed. For a data set around 50,000 items big, we saw query times of 2-10 seconds, and a DAILY cost of $15-20 for that endpoint alone. (We ended up hosting an index off-site in Redis and cutting query times to 400-700 ms, FWIW). This example code, while algorithmically interesting, is dangerous to host on App Engine for those worried about cost or latency.
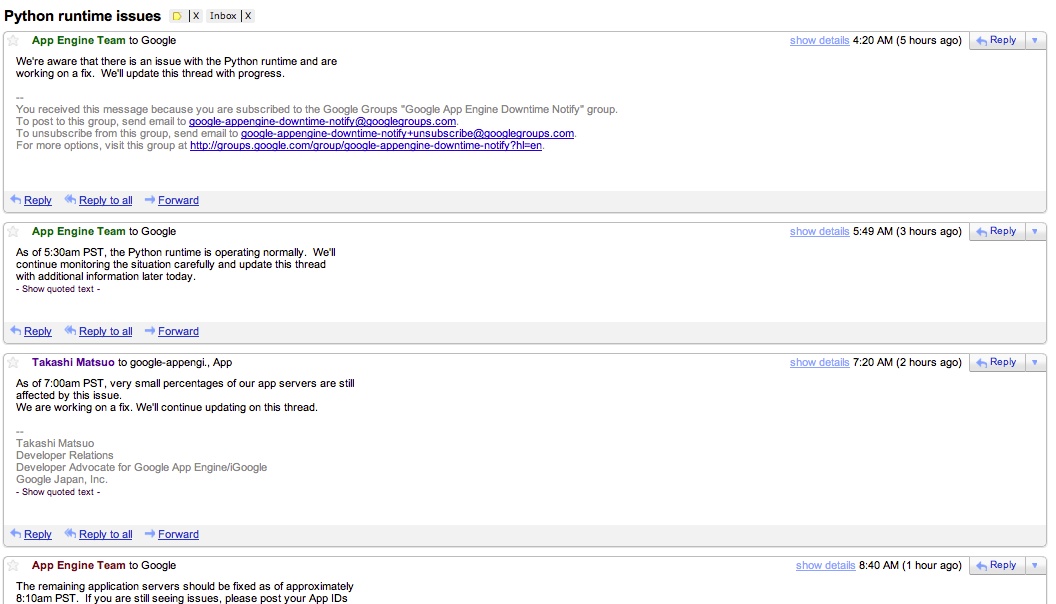
Perhaps the most frustrating aspect of GAE is the overall uptime of the service. Check the Google App Engine status page and you'll probably find green checkmarks across the board going back all week. Ask anyone actually on the service and they'll tell you that GAE will stop serving your web app for minutes to hours at least once a week, probably more. From my empirical observation, the status page will report emergent problems 60-70% of the time, but will permanently record problems less than 10% of the time (meaning you see a yellow exclamation mark on that day if you check its history). Truth-in-uptime was a topic I emailed and posted about many times, to no avail. There is a moral hazard involved in self-reported uptime that Google has not confronted.
Case in point: On Tuesday, March 8, 2011, GAE sent around emails to the google-appengine-downtime-notify@googlegroups.com email list reporting downtime in the python runtime. A check of the GAE status page shows no acknowledgement of this downtime.
This is a matter of personal preference. I did not like the django design patterns I ended up using and after which I modeled my code. I find our current Sinatra-based implementation cleaner and easier to understand. Python + django is verbose, its templating system is obtuse, and its testing framework is, well, I don't know because I've never seen it. This point is a religious one, so I'll leave it be, but I am unlikely to choose python as a tool again for anything that touches the Internet that is not purely computational in nature (and even then...).
To put it bluntly: it will take you days to extract data sets of any meaningful size (100GB+), and the export process is multi-step and fraught with errors. I tried and failed to migrate our data half a dozen times. For a large data set, I would budget at least one week, IF you know exactly what your doing and how/where you want the data to go. Thus, after you've tried and failed a few times, THEN give yourself a week.
OK, the true point of this is not to convince anyone of any particular position about GAE; instead it's to offer whatever wisdom I can about getting off of GAE to those who have come to that decision.
The plan of attack for data migration is as follows:
Google provides a command-line tool to automatically read your data and generate a YAML file that is used as a template for export. Simply run:
You can see more about this step at http://code.google.com/appengine/docs/python/tools/uploadingdata.html Note that this template file is incomplete when initially generated. First, you have to specify a "connector" - basically the final export format of your data. I only ever attempted to use CSV; I have no experience with any others. You will have to run a find/change through the code of:
to
In addition, any foreign key you may have had in your model will need its type specified. You will need to find/change the value in each of the instances of:
To the appropriate model type.
The extraction process is by far the most painful. Google essentially provides you a set of python scripts that spin up arbitrary numbers of worker threads to download your data. I generally would use 50 threads at a time and a really high bandwidth and results per query limit. Unfortunately, if the data store starts acting up, Google's code uses an exponential backoff algorithm that could cause the export process to grind to a halt (I never actually saw it recover, it just gets slower). Moreover, because export processes take days, you will need to run a nohup background process, but Google's export script requires an interactive login.
Here is my suggestion: spin up a dedicated EC2 instance, push your code and install Google App Engine linux, embed your username/password directly into the script, remove the exponential backoff, and then run the following:
If you're lucky, this process will actually export data. If you're unlucky, your data is stuck in GAE for good. In one application, I had made several model changes over the span of a few months. Despite my best efforts, out of nearly 100,000 records, I was only able to export 16. I have no idea why, and assume that data is lost forever. Those with an enterprise service account could probably receive additional help if they experience this kind of blocking issue. Fortunately, I was able to export all of my core data out of my main application.
During the migration, you can track the process by running a tail command on the bulkloader log files. It will tell you how many records it has exported in total. Compare this to the total number of records listed in your bulkloader.yaml file and you will have a sense of how long the process will take, but as I said before, expect it to take hours/days for large data sets.
Most of the time, the script will output a CSV file with your raw data. For my most common and most important data type, this did not happen. Instead you are left with a sqlite file tens of gigabytes big. For example, if you've done things like add date fields to a model, Google's exporter will choke when the date parser encounters null on the records added prior to the existence of the field.
Because it could take days to create that SQLite file, if you do encounter errors, I found the best approach is to write python code to directly and serially access the data in the sqlite file and export it as raw CSV/text/whatever.
Here is a script to directly export a message object from the SQLite file to CSV. Note that you would have to put google_appengine in your path in order to find the requisite libraries:
Obviously most of the technical nuances in this step will be a function of the datastore that you have chosen. I can say a few words about this however:
I have no insight into the future of Google App Engine. While Google is clearly rolling out new features in the product, it seems to continue to ignore the two critical issues of uptime and data store latency. New features like taskqueue constantly suffer from downtime from what I observed. GAE is offering enterprise support, and now offers a high-reliability datastore, which are both positive steps.
Unfortunately, for my app, Google App Engine was slow, unreliable, and expensive, and there was absolutely nothing I could do about it.
Having now hosted this app fully on Google, and now fully on EC2, I can say, empirically, that for the same daily price we are able to host an app roughy 1 order of magnitude larger.
Thankfully we had forgiving users, and today our app continues to grow running on EC2. Despite my early reticence, I have become a server guy, and am all-in with tools like Redis, Membase, and Sinatra + Ruby. I had to rewrite the whole server from scratch in ruby, and write much of my own monitoring code. In retrospect, to build a true consumer web application with real scaling demands, there was no other way. You either scale by hand or not at all; there is no magic scaling button. Web applications are stacks, every part of the stack will fail at some point, and you must be able to dive in and fix it, without waiting, without asking permission, without emailing or nagging anyone. I cannot imagine doing this again at a level of abstraction any higher than EC2. (We briefly tried Heroku but gave up, that's another post). Anyhow, EC2 has had its share of difficulties, but overall we're happy, and it's a much better infrastructure and architecture than what we left behind.
Good luck to everyone out there trying to build big, scalable, consumer apps. IMHO, it's one of the most difficult things to do in software, and when you do find a passionate market, it only gets harder. But, it'll give you good stories to tell, and maybe if you're lucky, you'll make a dollar or two.
Update: February 27, 2011: My good friend at Google has asked me to include a link to this blog post announcing the release of the High Replication Datastore. I have no experience with the HR Datastore; it was released after I deployed my app.
{kind=link}
{kind=link}