Classifying Web Pages
CS229 Project
Ulises Robles and Mark Chavira
1 Introduction
1.1 Project Overview
- We used a Naive Bayes Learner with a Gaussian model for class conditional probabilities.
- We ran experiments using different types of features: words only vs. words, punctuation, html tags, and other types of tokens.
- We ran experiments with features selected using different techniques: average mutual information vs. pointwise mutual information vs. chi-squared.
- We ran experiments using different types of feature counts: normalized for document length vs. un-normalized.
Equation 1
1.2 Project Resources
Student Faculty Staff Course Project Department Other
- Student
- Faculty
- Project
- Course
- JLex [2], a java version of Lex, to extract words and other tokens from our documents.
- Weka [3], a learning framework, to provide routines for input of data and cross-validation.
- Several Java programs and Perl scripts we wrote to help choose features, extract feature counts from documents, and learn from feature counts using Naive Bayes.
2 Experiments
- Divide the data into training and test sets. For example, we might use all pages originating from the University of Wisconsin as our test set and all other pages as our training set.
- Choose the types of the features by which to classify. For example, we might choose to count occurrences of specific words in the pages.
- Choose the exact features by which to classify. For example, we might choose to count the words "cow", "cat", and "dog".
- Choose how to represent extracted features. For example, we might divide each word count by the total number of words in the document.
- Run the learner and test the results.
2.1 Training Set
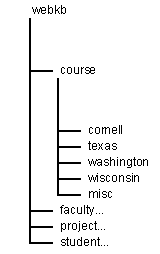
Figure 1 Webkb Directory Structure
Underneath Webkb/ are directories that divide the
pages according to their classification. Underneath each class directory,
are directories that sub-divide pages according to the Universities from
which they originate. Many of the pages come from Cornell University (226
pages) and from the Universities of Texas (252 pages), Washington (255
pages), and Wisconsin (308 pages). Pages inside the misc/ directory (3158
pages) originate from Universities other than these four. We ran experiments
using the following training and test sets:
|
Training Set
|
Test Set
|
|
{Webkb} - {Cornell}
|
{Cornell}
|
|
{Webkb} - {Texas}
|
{Texas}
|
|
{Webkb} - {Washington}
|
{Washington}
|
|
{Webkb} - {Wisconsin}
|
{Wisconsin}
|
|
{Webkb}
|
Ten-Fold Random Cross Validation
|
2.2 Feature Set Types
- Word counts.
- Token counts.
2.3 Feature Selection
- Average Mutual Information with respect to the class.
- Point-wise mutual information with respect to the class.
- Chi-Squared.
2.4 Normalization
2.5 Summary of Parameters
3 Results
3.1 Test Set
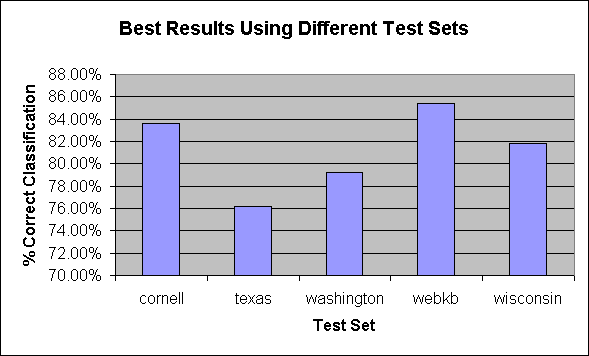
Figure 2 Best Results Using Different Test Sets
3.2 Feature Type
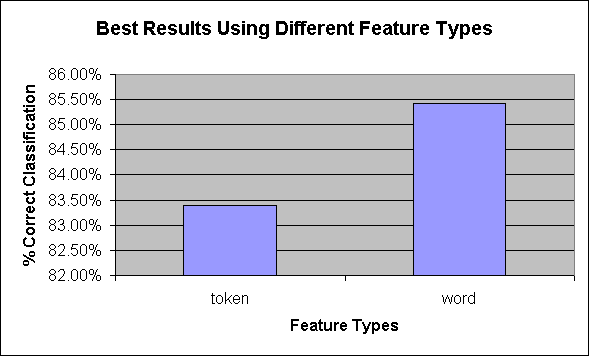
Figure 3 Best Results Using Different Feature Types
3.3 Feature Selection Method
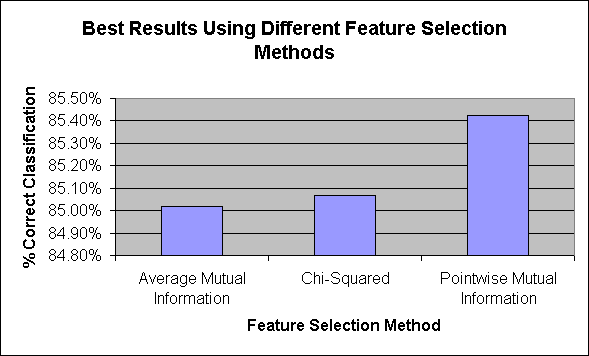
Figure 4 Best Results Using Different Feature Selection Methods
3.4 Normalization
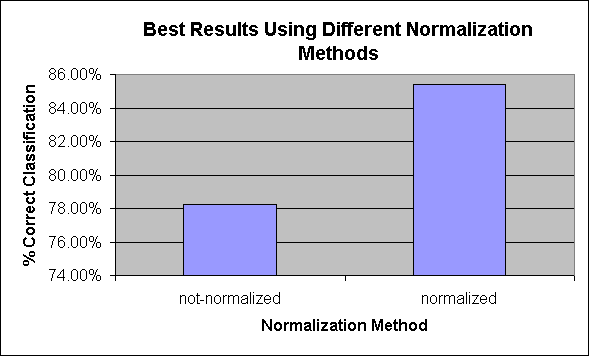
Figure 5 Best Results Using Different Normalization Methods
3.5 Summary of Parameters
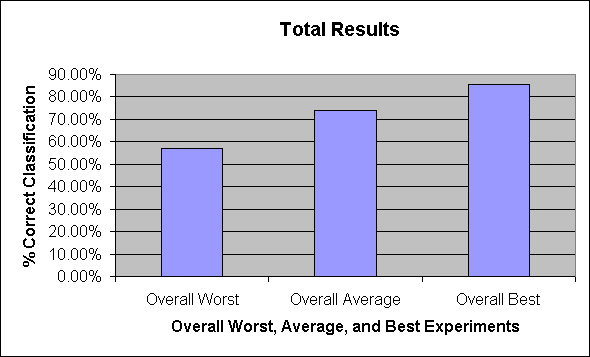
Figure 6 Total Results
A complete listing of results follows:
|
Test Set
|
Feature Type
|
Feature Extraction
|
Normalized
|
% Correct Classification
|
|
cornell
|
token
|
Average Mutual Information
|
no
|
68.58%
|
|
cornell
|
token
|
Average Mutual Information
|
yes
|
80.53%
|
|
cornell
|
token
|
Chi-Squared
|
no
|
70.35%
|
|
cornell
|
token
|
Chi-Squared
|
yes
|
81.86%
|
|
cornell
|
token
|
Pointwise Mutual Information
|
no
|
70.35%
|
|
cornell
|
token
|
Pointwise Mutual Information
|
yes
|
81.86%
|
|
cornell
|
word
|
Average Mutual Information
|
no
|
69.91%
|
|
cornell
|
word
|
Average Mutual Information
|
yes
|
80.97%
|
|
cornell
|
word
|
Chi-Squared
|
no
|
70.80%
|
|
cornell
|
word
|
Chi-Squared
|
yes
|
81.42%
|
|
cornell
|
word
|
Pointwise Mutual Information
|
no
|
70.80%
|
|
cornell
|
word
|
Pointwise Mutual Information
|
yes
|
83.63%
|
|
texas
|
token
|
Average Mutual Information
|
no
|
57.14%
|
|
texas
|
token
|
Average Mutual Information
|
yes
|
71.83%
|
|
texas
|
token
|
Chi-Squared
|
no
|
57.54%
|
|
texas
|
token
|
Chi-Squared
|
yes
|
73.02%
|
|
texas
|
token
|
Pointwise Mutual Information
|
no
|
57.94%
|
|
texas
|
token
|
Pointwise Mutual Information
|
yes
|
71.83%
|
|
texas
|
word
|
Average Mutual Information
|
no
|
61.51%
|
|
texas
|
word
|
Average Mutual Information
|
yes
|
76.19%
|
|
texas
|
word
|
Chi-Squared
|
no
|
64.68%
|
|
texas
|
word
|
Chi-Squared
|
yes
|
76.19%
|
|
texas
|
word
|
Pointwise Mutual Information
|
no
|
57.54%
|
|
texas
|
word
|
Pointwise Mutual Information
|
yes
|
75.40%
|
|
washington
|
token
|
Average Mutual Information
|
no
|
67.45%
|
|
washington
|
token
|
Average Mutual Information
|
yes
|
73.73%
|
|
washington
|
token
|
Chi-Squared
|
no
|
69.80%
|
|
washington
|
token
|
Chi-Squared
|
yes
|
72.16%
|
|
washington
|
token
|
Pointwise Mutual Information
|
no
|
68.63%
|
|
washington
|
token
|
Pointwise Mutual Information
|
yes
|
75.69%
|
|
washington
|
word
|
Average Mutual Information
|
no
|
67.84%
|
|
washington
|
word
|
Average Mutual Information
|
yes
|
77.25%
|
|
washington
|
word
|
Chi-Squared
|
no
|
69.41%
|
|
washington
|
word
|
Chi-Squared
|
yes
|
79.22%
|
|
washington
|
word
|
Pointwise Mutual Information
|
no
|
69.02%
|
|
washington
|
word
|
Pointwise Mutual Information
|
yes
|
76.86%
|
|
webkb
|
token
|
Average Mutual Information
|
no
|
67.75%
|
|
webkb
|
token
|
Average Mutual Information
|
yes
|
82.81%
|
|
webkb
|
token
|
Chi-Squared
|
no
|
68.80%
|
|
webkb
|
token
|
Chi-Squared
|
yes
|
82.90%
|
|
webkb
|
token
|
Pointwise Mutual Information
|
no
|
68.54%
|
|
webkb
|
token
|
Pointwise Mutual Information
|
yes
|
83.40%
|
|
webkb
|
word
|
Average Mutual Information
|
no
|
69.18%
|
|
webkb
|
word
|
Average Mutual Information
|
yes
|
85.02%
|
|
webkb
|
word
|
Chi-Squared
|
no
|
69.42%
|
|
webkb
|
word
|
Chi-Squared
|
yes
|
85.07%
|
|
webkb
|
word
|
Pointwise Mutual Information
|
no
|
69.25%
|
|
webkb
|
word
|
Pointwise Mutual Information
|
yes
|
85.43%
|
|
wisconsin
|
token
|
Average Mutual Information
|
no
|
77.60%
|
|
wisconsin
|
token
|
Average Mutual Information
|
yes
|
77.27%
|
|
wisconsin
|
token
|
Chi-Squared
|
no
|
77.60%
|
|
wisconsin
|
token
|
Chi-Squared
|
yes
|
75.97%
|
|
wisconsin
|
token
|
Pointwise Mutual Information
|
no
|
76.62%
|
|
wisconsin
|
token
|
Pointwise Mutual Information
|
yes
|
79.87%
|
|
wisconsin
|
word
|
Average Mutual Information
|
no
|
77.60%
|
|
wisconsin
|
word
|
Average Mutual Information
|
yes
|
81.17%
|
|
wisconsin
|
word
|
Chi-Squared
|
no
|
76.30%
|
|
wisconsin
|
word
|
Chi-Squared
|
yes
|
81.82%
|
|
wisconsin
|
word
|
Pointwise Mutual Information
|
no
|
78.25%
|
|
wisconsin
|
word
|
Pointwise Mutual Information
|
yes
|
81.17%
|
4 Conclusions
- Test Set: The best performing experiment for each test set produced results in the 76%-85% range. Experiments using test sets corresponding to a single University performed worse than the experiment that used cross-validation. We can think of two reasons. First, the single University test sets are smaller, so a few anomalous pages can skew results. Second, as expected, it appears that the classifier has more difficulty classifying pages from a University that the learner did not see during the training process.
- Feature Type: For each pair of experiments that differed only in the feature type parameter, using words consistently outperformed using words and other tokens. We surmise that using words performed better, because the tokens were so numerous that their presence began to lose meaning. For example, documents contain many more periods than occurrences of a typical word. It is somewhat disappointing that including tokens other than words did not improve performance. However, more research is needed in this area, since we did not exhaust the possibilities. For example, we counted tags. We could have been more specific and counted links, pictures, etc.
- Feature Selection: Using Pointwise Mutual Information scored slightly higher than the other two methods, but scores were very close. In fact, different feature selection methods came out on top depending on other parameters for the experiments. In general, pointwise mutual information performed slightly better than the other two feature selection methods.
- Normalization: Using normalized counts consistently performed significantly better than using un-normalized data. This result is reasonable. Again, one would expect a page with a few occurrences of the word "my" to indicate a student page or a faculty page, but not necessarily if the page were 50,000 words long.
Test Set: Webkb Ten-Fold Stratified Cross Validation Feature Types: words only Feature Selection Method: pointwise mutual information Normalization: normalized for page length
5 Related Work/Literature
[1] Webkb Data Set [2] JLex [3] Weka Tools [Craven et. all] M. Craven, D. DiPasquo, D. Freitag, A. McCallum, T. Mitchell, K. Nigam, S. Slattery. 1998. Learning to Extract Symbolic Knowledge from the World Wide Web. Mitchell, Machine Learning, WCB/McGraw-Hill, 1997. Witten, Frank, Data Mining, Morgan Kaufmann, 1999.
Send comments to: Mark Chavira and Ulises Robles-Mellin
Last modified: Mon. Mar 13, 2000